
Redis Cluster is a distributed implementation of Redis that provides horizontal scalability and high availability without compromising on performance. It ensures data sharding, replication, and automated failover, making it a robust choice for handling large-scale, high-performance applications. In this blog, we will explore the architecture of Redis Cluster, its components, data sharding mechanism, replication and failover process, and communication protocols.
Redis Cluster Architecture
Redis Cluster divides the dataset across multiple nodes, ensuring data redundancy and availability through replication. It is designed to handle large volumes of data and high request rates by distributing the load evenly across the cluster.
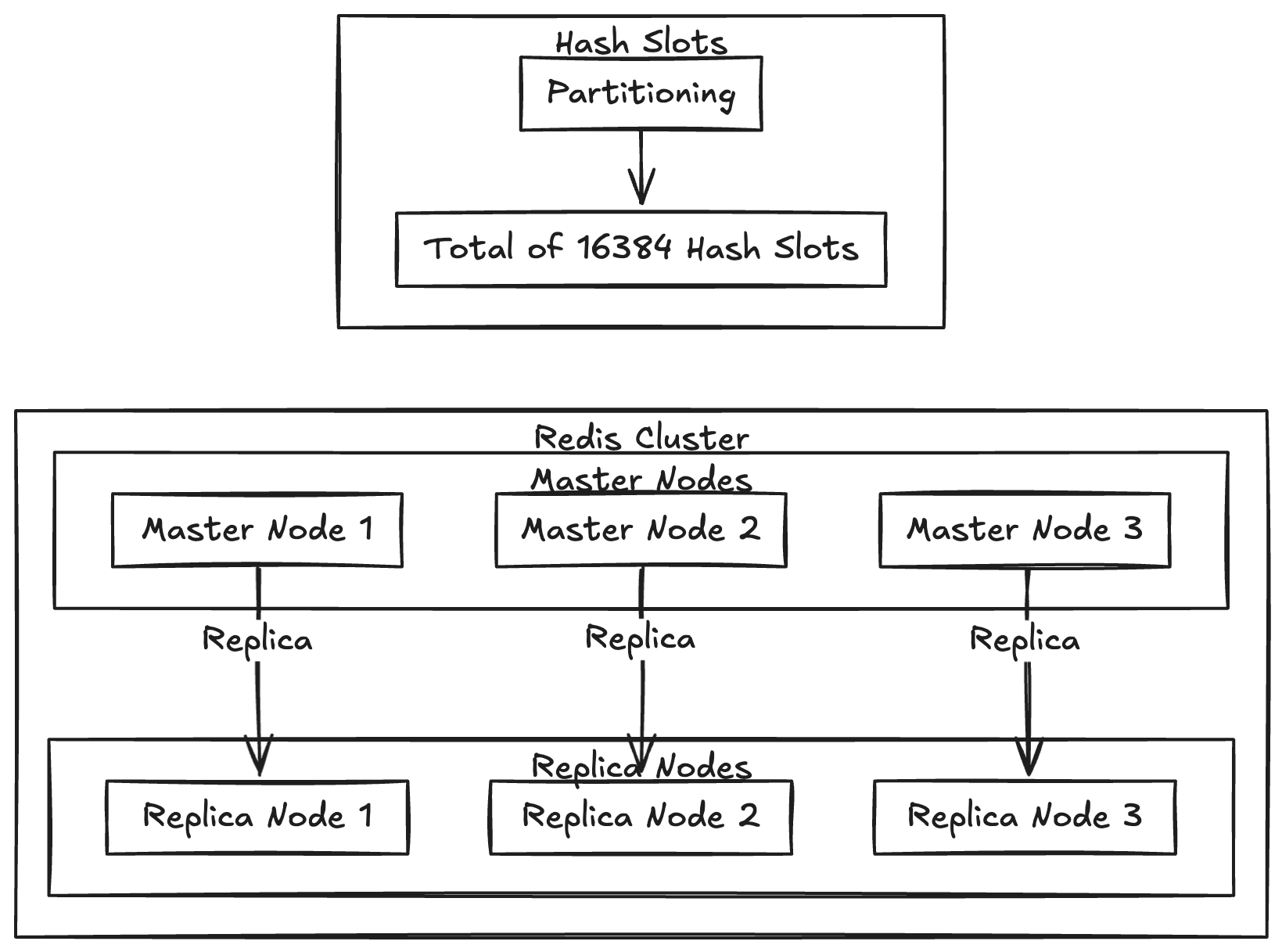
Cluster Nodes
Redis Cluster consists of two types of nodes: Master Nodes and Replica Nodes. Together, they ensure the cluster's scalability, data redundancy, and fault tolerance.
Master Nodes
- Dataset Management: Each master node is responsible for managing a unique portion of the dataset. The dataset is partitioned based on hash slots, ensuring balanced data distribution.
- Request Handling: Master nodes handle all read and write requests for the keys assigned to their hash slots, maintaining direct access to the data they own.
- Replication: Data on each master node is replicated to one or more replica nodes to provide redundancy and failover support.
Replica Nodes
- Redundancy: Replica nodes store copies of the data from their associated master nodes, ensuring data availability in case of a failure.
- Load Offloading: Replicas can handle read-only requests, thereby reducing the workload on master nodes and improving cluster performance.
- Failover: In the event of a master node failure, a replica is automatically promoted to master, ensuring uninterrupted service.

Data Sharding
Data sharding is a key feature of Redis Cluster that allows the dataset to be distributed across multiple nodes, enhancing scalability and performance.
Hash Slots
- Partitioning: The dataset is divided into 16384 hash slots, ensuring fine-grained control over data distribution.
- Key Assignment: Each key is assigned to a specific hash slot using the CRC16 hash function, ensuring consistency in data placement.
- Distribution: The hash slots are evenly distributed among the master nodes, ensuring balanced load and optimized resource utilization.
Data Partitioning
- Load Balancing: The distribution of keys across hash slots and nodes ensures that no single node becomes a bottleneck.
- Rebalancing: When nodes are added or removed from the cluster, hash slots are reassigned to maintain an even distribution of data.

Replication and Failover
Replication and failover are critical to maintaining data availability and minimizing service disruption in Redis Cluster.
Replication
- Data Redundancy: Each master node replicates its data to one or more replica nodes, ensuring that data is not lost in case of a failure.
- High Availability: Replicas act as backups, ready to take over when needed, maintaining data availability.
Failover
- Automatic Failover: If a master node fails, a replica is automatically promoted to master, ensuring continuous operation.
- Minimized Downtime: The failover process is quick, keeping service interruptions to a minimum.
Communication
Effective communication is essential for Redis Cluster to manage node interactions and client requests efficiently.
Node-to-Node Communication
- Binary Protocol: Redis Cluster nodes use a lightweight binary protocol for fast and efficient communication.
- Heartbeat Messages: Nodes send periodic heartbeat messages to monitor the health and status of other nodes in the cluster.
Client Communication
- Client Connection: Clients can connect to any node in the cluster, which then acts as a gateway for routing requests.
- Request Redirection: If a client sends a request to the wrong node, the cluster responds with a
MOVEDorASKredirection message to guide the client to the correct node.

Conclusion
Redis Cluster is a powerful solution for managing large datasets and ensuring high availability and performance. Its architecture, data sharding, replication, and failover mechanisms make it an ideal choice for distributed caching and in-memory database needs. In the upcoming blogs, I will explore each of these components—Cluster Nodes, Data Sharding, Hash Slots, Replication, and Failover—in detail, providing in-depth insights into their implementation and practical use cases.




